at dos command enter pip.exe install pyautogui
https://www.mapbox.com/navigation/ mapping API
https://docs.mapbox.com/api/navigation/#directions
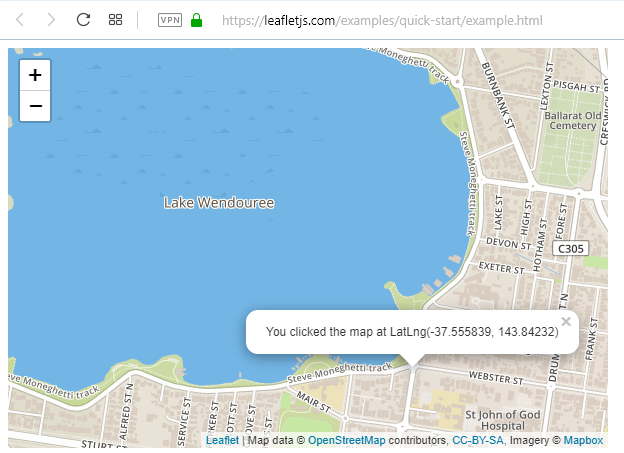
https://leafletjs.com/examples/quick-start/
https://leafletjs.com/examples/quick-start/example.html
https://realpython.com/python-basics/
https://realpython.com/python-web-scraping-practical-introduction/
https://realpython.com/python-virtual-environments-a-primer/
https://realpython.com/python-first-steps/
https://scrapy.org/ May be better than https://www.crummy.com/software/BeautifulSoup/
Start Power Shell and install beautifulsoup4->bs4
pip install bs4
python
>>> import bs4
>>> from urllib.request import urlopen as uReq
>>> from bs4 import BeautifulSoup as soup
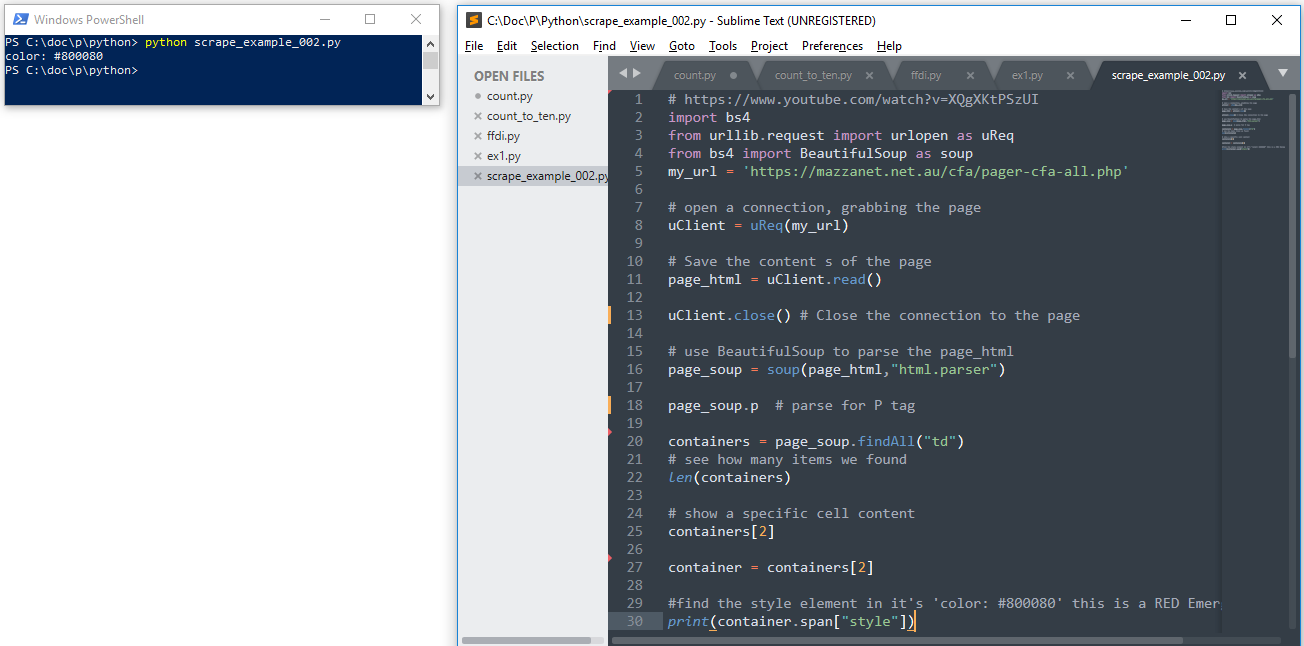
The code scrape_example_002
SearchMe = "The apple is red and the berry is blue!"
print(SearchMe.find("is"))
print(SearchMe.rfind("is"))
print(SearchMe.count("is"))
print(SearchMe.startswith("The"))
print(SearchMe.endswith("The"))
print(SearchMe.replace("apple", "car")
.replace("berry", "truck"))
Pasting an image on another image

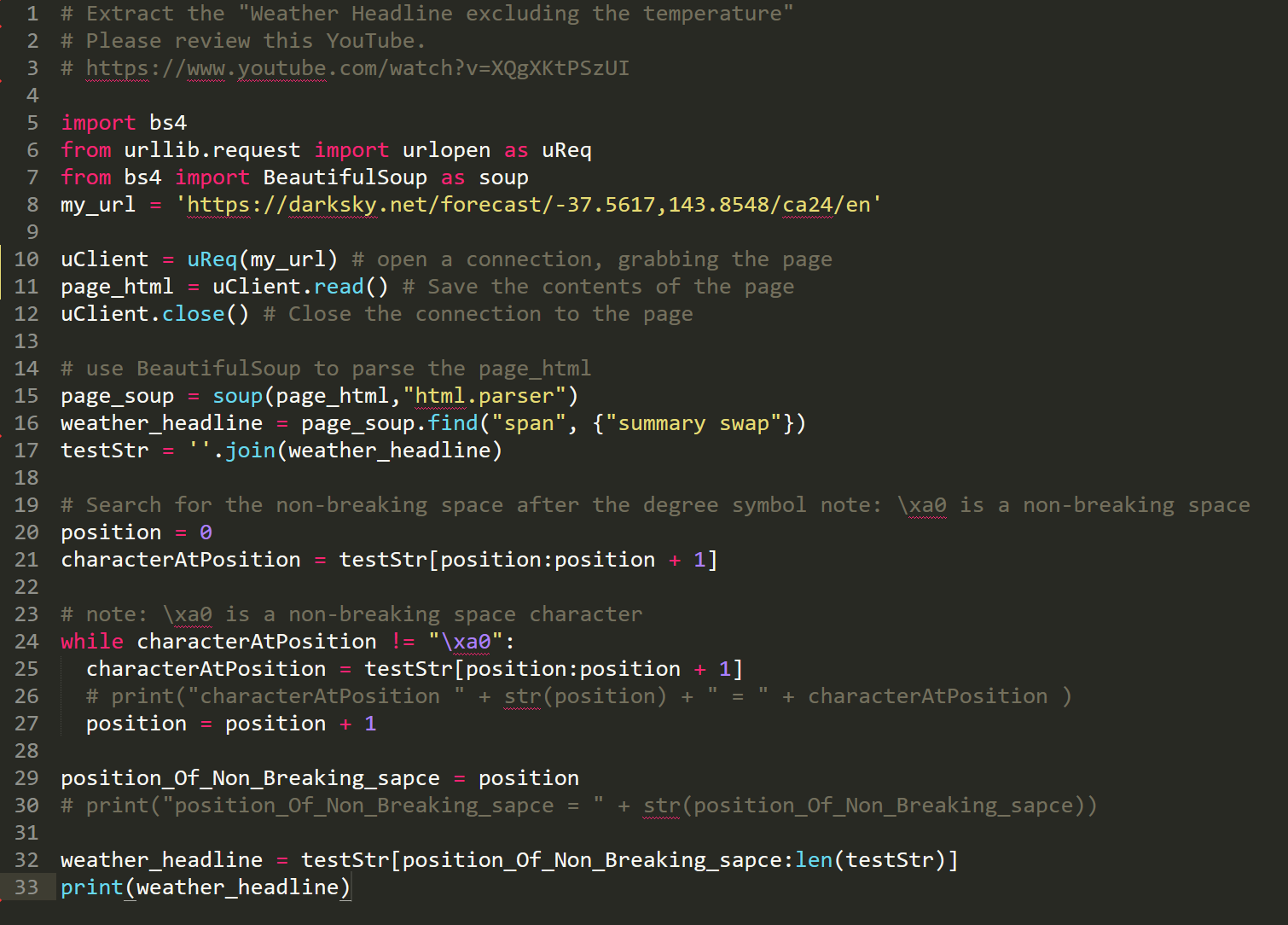
# Extract the "Weather Headline excluding the temperature" # Please review this YouTube. # https://www.youtube.com/watch?v=XQgXKtPSzUI
import bs4 from urllib.request import urlopen as uReq from bs4 import BeautifulSoup as soup my_url = 'https://darksky.net/forecast/-37.5617,143.8548/ca24/en'
uClient = uReq(my_url) # open a connection, grabbing the page page_html = uClient.read() # Save the contents of the page uClient.close() # Close the connection to the page
# use BeautifulSoup to parse the page_html
page_soup = soup(page_html,"html.parser")
weather_headline = page_soup.find("span", {"summary swap"})
testStr = ''.join(weather_headline)
# Search for the non-breaking space after the degree symbol note: \xa0 is a non-breaking space position = 0 characterAtPosition = testStr[position:position + 1]
# note: \xa0 is a non-breaking space character
while characterAtPosition != "\xa0":
characterAtPosition = testStr[position:position + 1]
# print("characterAtPosition " + str(position) + " = " + characterAtPosition )
position = position + 1
position_Of_Non_Breaking_sapce = position
# print("position_Of_Non_Breaking_sapce = " + str(position_Of_Non_Breaking_sapce))
weather_headline = testStr[position_Of_Non_Breaking_sapce:len(testStr)] print(weather_headline)
Next to scrape:
https://www.accuweather.com/en/au/ballarat/15875/current-weather/15875